With over 13 million items, Wikidata is a vast repository of human- and machine-readable data, and with over 70 million edits in the last 11 month, its value as a data repository is growing fast. Much of that value is stored in statements about items, and the connections between items.
42 might take a while
Surprisingly, ways to query this data behemoth are quite limited. There is text search, which will find you items with certain labels, and there is an API which can get information about a specific item and its properties. And yet, a way to ask more complex questions is nowhere in sight. Getting a list of people born in New York is currently impossible, without resorting to rather slow and tedious third-party tools (I should know; I wrote some of them). “Simple” queries are being worked on, but due to personnel priorities, as well as the nature of the underlying data storage, it might be quite a while to get answers to compound queries from Wikidata itself.
Worse, even if statements were present as “proper” database tables (they currently exists only as JSON blobs, if you really want to know), developers would be faced with a variety of the “category tree” problem that we all know and love on Wikipedia: Trees are not quickly and easily searched in databases, turning category tree intersections and related operations into horror stories to scare other programmers around a virtual campfire. Several variations of “CatScan” exist, but cannot really solve these issues. The same kind of challenges will hit Wikidata for “subclass of” and “parent taxon” chains that need following and branching.
So, a while ago, I asked the Wikidata section of Wikimedia Labs for a server to try out an idea of mine: What if I could keep the entirety of Wikidata in memory, as one giant, interlinked data structure? Is that possible? Would complex searches be quick enough? To make a long story short: Yes, and yes 🙂 The machine, with the software I dub “Wikidata Query” (WDQ for short), has been online for a while, and some people know about it, but with some recent updates to the code, interface, and documentation, I felt it’s time to write it up in a blog post.
The bridges of Germany
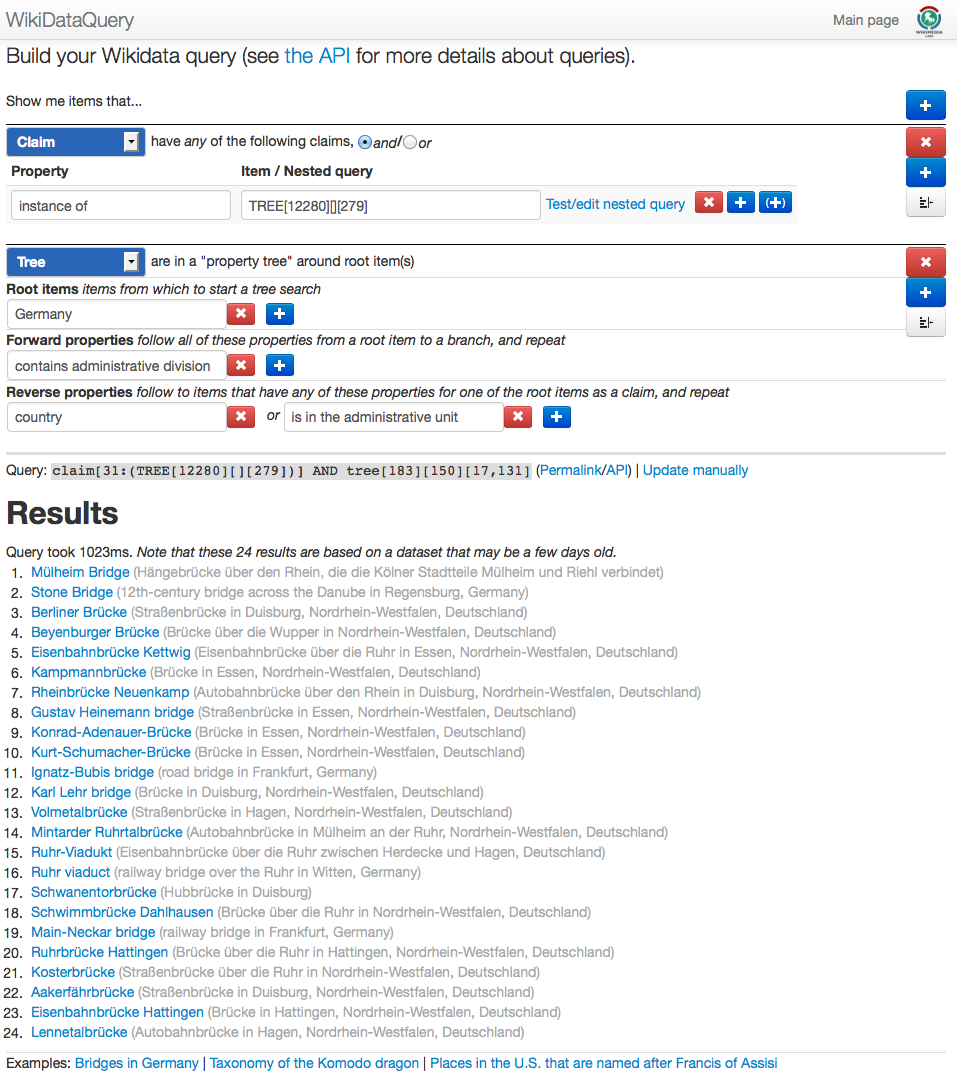
The query designer with the “bridges in Germany” example query.
Why does this need to be so complicated? What is the problem I am trying to solve? Let’s look at an example: I want to get a list of all the bridges in Germany. This sounds simple enough at first, but the devil is in the detail. What is a bridge, at least in Wikidata? Well, obviously anything that is an “instance of: bridge”, right? Right. And wrong, because that would be incomplete. This is a bridge in Germany, but it is an “instance of: railway bridge”, with “railway bridge” being a “subclass of: bridge”. This is a “direct” subclass, but since there is no “chain length limit” in Wikidata, this might go over several “subclass steps”. Thus, a bridge in Wikidata is an “instance of” anything that is a “subclass of” bridge, or “subclass of subclass of” bridge, etc. Basically, we need to construct a “reverse subclass tree” (reverse because we follow “incoming” links from the root) of everything that has “bridge” at its root, and get all the instances of all these bridge subclasses.
Now we have a list of all bridges. ALL bridges, worldwide. But we want only bridges in Germany, remember? So, how do we know that something (bridge or otherwise) is in Germany? As you might have guessed, “country: Germany” is not going to cut it. This time, we need all items that are leafs of the “is in administrative unit” reverse tree that can be traced back to the root “Germany”. For the previously mentioned bridge, that’s five hops.
“All” we need to do now is to find the items that are in both the “bridge” and the “Germany” lists of items, and we’re done! This sounds like a lot of work, and it is! However, thanks to the in-memory implementation (currently taking an easy 9GB of RAM, including multilingual item labels), this query takes only 0.8 seconds, which is quite reasonable IMO.
Designer code and raw query power
While this works nicely, and could be the basis for many other tools, constructing the query (which in this case, is obviously “claim[31:(TREE[12280][][279])] AND tree[183][150][17,131]” ) requires some basic programming skills, and a lot of time to find the item and property IDs. Also, the JSON output, while perfectly machine-readable, is not exactly easy on the eye. Therefore, I also wrote a query designer that should cater to a larger audience. It offers combinations of searched for claims, negative claims (“does not have a claim/property”), perfect matches for strings (e.g., “has this VIAF ID”), and the aforementioned chains or trees.
Due to lack of manpower, the query designer does not (yet) cover all possibilities the API offers. Manually constructed queries can search for date ranges per property (as in “born between dates X and Y”), or for locations around a point. All of these can be combined with AND/OR, grouped, and (in some cases) use nested subqueries, which makes the query language quite powerful.
There are a few minor drawback in all of this: WDQ is based on the Wikidata dumps, static snapshots that are made at more-or-less regular intervals. I do update WDQ with the daily “differential” dumps, so it should never be more than 24h out of date, but in the ever-changing world of Wikidata that can feel like an eternity. Also, neither qualifiers nor sources are supported yet.
If you would like to build your own tools on top of WDQ (which I would welcome very much!), have a look at the API documentation, with details on how to construct a query, and advanced/experimental features such as properties and labels. I would also welcome help with maintaining, improving, and extending the code (hereby GPL 2+, code on Bitbucket).
4 Comments
Hi
Your links to wikidataquery.eu redirects to http://wikidata-wdq-mm.instance-proxy.wmflabs.org which is not reachable.
Is that a temporary issue or something else ?
Thanks EPY, I updated the URLs, should work now.
Hi Magnus
Thanks for this great tool.
http://wikidata-wdq-mm.instance-proxy.wmflabs.org is still not reachable.
Best regards
Jean
@Jean: That’s because the URL is http://wdq.wmflabs.org/